
1 更高级的算法牵扯到更多重的循环和复杂的计算,尤其是现在人工智能的算法尤其如此。有些历史知识的人能够了解到,人工智能的很多基本算法其实近百年之前就有了,但是当时的计算机技术达不到去实现这些算法的要求,因此当今计算机的技术和当时已经不是在一个量级上面,因此人工智能等方案才有被重新提上日程,获得飞速的发展。也就是说,当人的思想超越当今的技术的时候我们只能等待,但是当当今的技术已经能够赶上人的思想,我们将会无所不能。
2 这一部分的内容主要是充分调用计算机的性能甚至是调用n台计算机形成集群形式使得算法能够快速的运算和提升整个程序的运行效能。
3 MATLAB2009之后,退出了并行计算工具箱(Parallel Computing Toolbox,PCT)和并行计算服务(Distibuted Computing Server,DCS),通过PCT和DCS用户可以实现基于多核平台、多处理器平台和集群平台的多种并行计算任务。PCT除了支持通用的上述功能之外还增加了GPU单元的支持。在MATLAB中,可以通过PCT、MEX文件等多种方式利用GPU来完成数据处理功能。
首先要考虑的几个问题:
1)并行计算的平台:
单计算机MATLAB支持8个worker(2010b)版本、如果需要多台计算机组成集群,需要利用PCT和DCS共同完成,如果需要GPU运算,利用PCT、MEX文件技术来完成。
2)并行计算的复杂程度:
当然MATLAB来进行并行计算省去了很多繁琐的底层工作,相对快捷和简单。
比如利用parfor循环,可以对for循环进行并行处理,利用SPMD可以对单个程序多组数据情况进行并行处理。这里要尽量选择MATLAB并行计算工具箱内置的并行结构。
3)并行计算的数据通信问题:
并行计算的两个目的:第一是提高计算效率,第二是提高计算机的利用率。第一个问题比较绒里理解就是比如单个问题CPU计算需要10个小时,那么采用10个CPU进行计算可能只需要1.5小时就可以完成。
相见恨晚的功能:profiler 代码分析器
4 profiler viewer,就会弹出代码分析器的窗口,然后再窗口输入想要测试的脚步等。就能得出段脚步那些地方用时最多
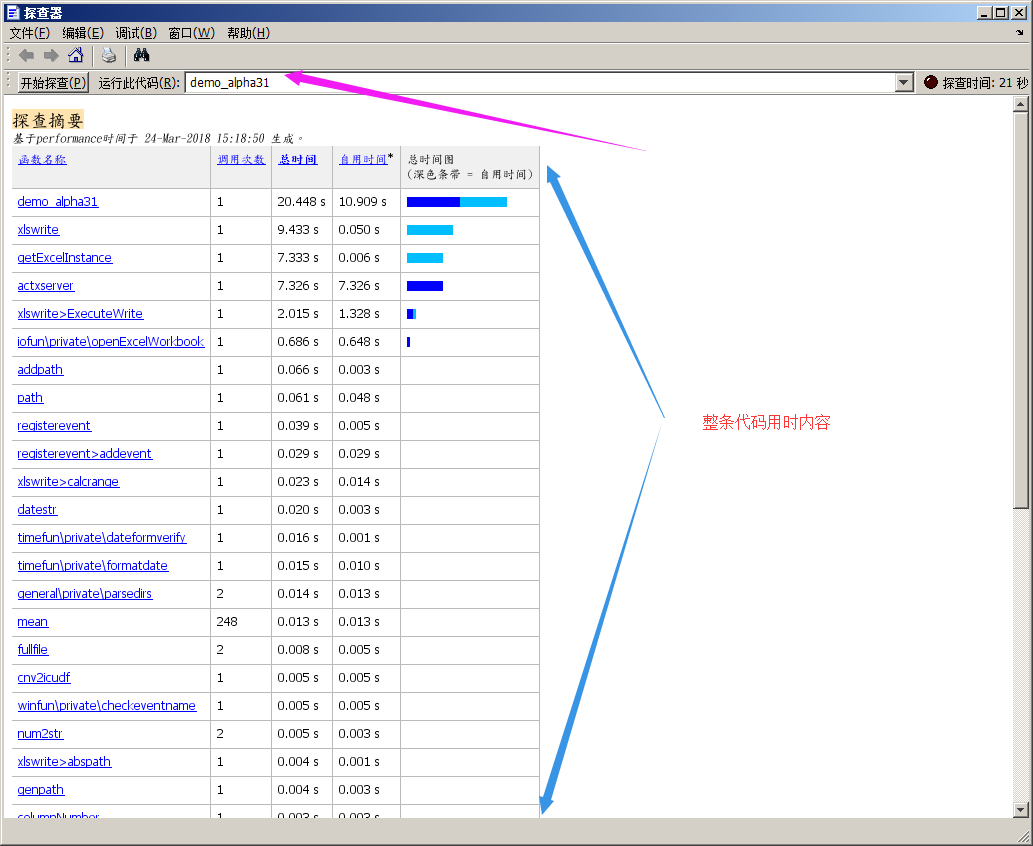
可以据此来修正代码,改进代码
5 提升代码运算效率在代码编写上注意的几个问题:
1)尽量用向量化来替代for和while循环的运算。

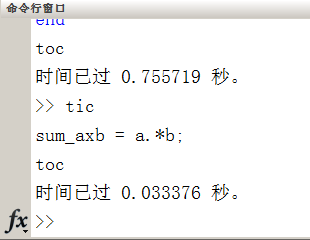
采用向量化,对于大型的运算,时间要快于for循环或者while循环。
2)还有一些经过优化的向量运算函数:
all,判断数值阵列是否全部非零
any,判断数值阵列是否有非零元素
reshape,变化数值阵列的各维元素数据
find,返回非零元素在阵列中的位置和其值
sort,将数组按照升序排列
sum,求数组的和
repmat,扩展阵列
is等函数。。。。
相见恨晚的功能:利用parfor对for循环进行并行(PCT工具箱中的函数)
6 在程序设计中,往往最小化计算量的代码都是循环。循环分为两种:一种是固定次数的循环,另一种叫非固定次数的循环(while),在MATLAB程序中,提高循环计算效率往往是提高程序计算效率的关键。对于固定次数的循环,一般有两种类型:一种是循环次数较大,单词循环的计算量较小;另一种是循环次数较小,单词循环计算量较大。采用MATLAB提供的parfor关键字就可以对这两种类型的循环实现多核或多处理器并行执行。
7 parpool 命令配置并行计算池(在2010版本之前的命令是matlabpool,后面版本都用这个命令来替代原先的命令)
8 不启动并行池,直接执行parfor程序不起作用。
9 当新欢次数设为100 000时,parfor执行的时间反而远远高于for循环的执行时间。这说明当循环次数较小的时候,通过parfor关键字对for循环体进行并行的效率很低。原因比较复杂,这里试着增加循环次数,观察parfor关键字对for循环体进行的效率变化,随着循环次数的增加,parfor关键字对for循环并行金酸的效率开始提高。在实际应用中,如果根据循环次数选择parfor关键字或者选择for关键字完成简单循环计算?由于MATLAB是解释型语言,而且已经封装了对选好进行并行计算的细节。很难通过分析和推导得到比较准确的结果。另外,不同的计算机对应的计算单元有很大差异,例如CPU个数和类型等,因此在parfor循环并行计算分析中,采用测试程序进行测试是十分必要的,这一点在前面已经得到充分的说明。这里,仍然沿用绘制并执行时间曲线的方法进行分析,通过测试程序绘制parfor的执行时间和for的执行时间随时间次数变化的曲线,人后对比两个时间曲线分析确定parfor关键字执行效率高于for关键字的临界点,即临街循环次数。
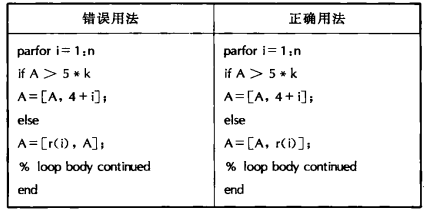
10 parfor的正确用法
1)简约变量只能出现在简约赋值操作的表达式中

2) 在同一个parfor循环内,对简约变量的操作一致

3)如果简约变量的操作是相乘或者链接【】,变量X或出在操作符前面,或处在操作符后面,但是X的位置必须恒定不变。
4)简约变量赋值应当满足结合律和交换律
11 parfor程序设计需要考虑的其他问题
1)变量名称(函数优先)
在MATLAB parfor循环代码块中,如果变量在循环之外没有定义或初始化,则MATLAB采用函数优先的原则,即MATLAB假定次变量为一函数名。
比如执行:
clear
N = 100
a = 1
parfor kk = 1:N
a = a+f(kk)
end
会报错。
2)显式使用变量
3)parfor中使用函数句柄
在parfor中调用函数句柄时,需要注意只能采用feval函数调用。如果在parfor循环中使用函数句柄,则代码MATLAB提示报错。
比如只能执行
N = 10
B = @sin;
parfor ii = 1:100
A2(ii) = feval(B,ii);
end
4)在parfor中调用递归函数
相见恨晚的功能:parpool常用的命令
1)parpool('local',2); % 在已知worker数列的情况下,打开几个worker
2)parpool; % 在默认条件下启动并行池,有几个worker打开几个workder
3)c = parcluster % 用句柄的形式条用并行池
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | >> c = parclusterc = Local Cluster Properties: Profile: local Modified: false Host: PC-201709010031 NumWorkers: 2 NumThreads: 1 JobStorageLocation: C:/Users/Administrator/AppData/Roaming/MathWorks/MATLAB/local_cluster_jobs/R2016b RequiresMathWorksHostedLicensing: false Associated Jobs: Number Pending: 0 Number Queued: 0 Number Running: 0 Number Finished: 0>> parpool(c)Starting parallel pool (parpool) using the 'local' profile ... |
4)poolobj = parpool;
delete(poolobj) %删除并行池
5)启动和关闭并行池的一组组合方式
| 1 2 3 4 5 6 7 8 9 | >> poolobj = parpool('local',2);Starting parallel pool (parpool) using the 'local' profile ... connected to 2 workers.>> delete(poolobj)Parallel pool using the 'local' profile is shutting down.>> poolobj = parpool; % 默认打开全部workerStarting parallel pool (parpool) using the 'local' profile ... connected to 2 workers.>> delete(poolobj)Parallel pool using the 'local' profile is shutting down. |
其中注意到,句柄poolobj有很多参数,当然这个也可以在MATLAB预设里面找到相关设置。但是这里对这些设置都是写啥东西,进行一下解释。当然可以用poolobj.内容,进行修改。
NumWorkers 组成并行池的workder个数
AttachedFiles 被发送到workers的文件和文件夹
Idle Timeout 闲置的并行池关闭前分钟表示的时间范围
Cluster 群集启动池,指定为群集对象 因为我们可以用集群化并行运算,如果没有集群,内容会显示本地
Connected 并行池中运行的族群
FevalQueue 要在并行池中运行FevalFutures队列
SpmdEnabled 是否可以运行SPMD代码
相见恨晚的功能:SPMD并行结构
12 SPMD(Single Program,Multiple Data)是MATLAB支持的另外一种并行结构。其对应的使用方式即相同程序、不同数据。SPMD并行结构比parfor并行解耦股更加灵活,但也引入更加复杂的数据类型和操作方法。
13 假定用户有一批数据文件需要处理,而且每个文件的处理程序相同,在这种情况下可应用SPMD并行结构。在SPMD并行结构中,用户可以获得每个worker的编号labindex和总的worker数据numlabs。这两项信息在parfor并行结构中是无法获取的。通过labindex和numlabs用户可以控制每个worker执行的计算任务。因此SPMD并行结构给用户提供了更大的自由度,用户可以控制更多的并行计算的细节。
14 SPMD并行结构需要依赖MATLAB并行计算池执行,因此SPMD并行结构执行之前,用户必须配置和启动MATLAB并行计算池。和parfor一样,用户既可以启动本地并行计算池,也可以启动集群并行计算池。本地并行计算池管理的workder与MATLAB client在同一计算节点中执行,集群并行计算池管理的worker与MATLAB client一般不再同一计算节点中执行。
15 SPMD并行结构通过spmd关键字启动,如下:
| 1 2 3 4 5 6 7 8 9 10 11 | spmd a = rand(labindex);end>> aa = Lab 1: class = double, size = [1 1] Lab 2: class = double, size = [2 2]>> class(a)ans =Composite |
可以看出a的形式比较奇怪,并不属于数值阵列,而是一种称之为composite的变量,关于composite变量,在后面会有详细结构。读者暂时可以认为a是一个元组阵列。
在MATLAB并行程序设计中,worker有时也被成为lab。二者区别在于,lab是一个中特殊的worker,各个lab之间可以相互通信和同步。而各个worker之间一般是独立的。执行SPMD的工作单元成为lab,这也是labindex和numlabs命名的由来。
16 SPMD的使用方法:
spmd
需要并行的主体
end